...
Datum | Versie | Auteur | Opmerkingen |
|---|---|---|---|
28-09-2005 | 0.1 | MvM | Creatie: Dai formataanpassingen |
07-11-2005 | 0.2 | MvM | Wijzigingen in Inleiding en hoofdstuk 4 in rood; nieuw |
16-11-2005 | 0.3 | MvM | Hoofdstuk 3 en 7 aangepast na review TvdV en RK |
25-11-2005 | 1.0 | MvM | Besproken en geaccepteerd in DAI project bijeenkomst |
21-12-2005 | 1.1 | MvM | Wijziging in 3.2.1 en 6 (Ophalen DAI); in 4.3 is veld |
26-01-2006 | 1.2 | MvM | Arceringen verwijderd; opmerking over naamsvariant- |
01-02-2006 | 1.3 | MvM | Nieuwe titel: DAI werkprocessen |
01-02-2006 | 1.3 | MvM | Toegevoegd: 3.2.2 Export van thesauruswijzigingen; |
12-02-2006 | 1.4 | MvM | Template voorbeelden en URL structuur Metis |
22-02-2006 | 1.5 | MvM | XML schema toegevoegd in Appendix 2; format |
05-04-2006 | 1.6 | MvM | Herziene versie met wijzigingen in rood; Appendix III |
16-06-2006 | 1.7 | MvM | Wijzigingen in XML schema in appendix 2; URL ipv |
27-06-2006 | 2.0 | MvM | Ongewijzigde eindversie |
...
Inhoud
1 #Referenties
2 #Inleiding
3 #Procesbeschrijving
3.1 #Initiële vulling
3.2 #Dagelijks gebruik
3.2.1 #Ophalen DAI
3.2.2 #Ophalen van Metis wijzigingen
3.2.3 #Export van thesauruswijzigingen
4 #Nieuwe velden
4.1 #Velden op gemeenschappelijk niveau
4.2 #Velden op lokaal niveau
4.3 #Velden van het onderzoeksblok
5 #Relatie tussen bestaande en nieuwe velden
6 #Benodigde URL's
7 #Matchen van persoonsnamen
I Metis export format
II Pica export format
II.I #XSD
II.II #XML document
III Thesaurus templates
IV Kwaliteitseisen
IV.I #Gegevens
IV.II #Procedures
IV.III #Documentatie
IV.IV #Systeemeisen
V Samenvoegen en splitsen van thesaurusrecords
| Anchor | ||||
|---|---|---|---|---|
|
2 INLEIDING ................................................................................................................................................. 4
3 PROCESBESCHRIJVING ......................................................................................................................... 5
3.1 INITIËLE VULLING ................................................................................................................................... 5
3.2 DAGELIJKS GEBRUIK .............................................................................................................................. 6
3.2.1 Ophalen DAI................................................................................................................................6
3.2.2 Ophalen van Metis wijzigingen....................................................................................................8
3.2.3 Export van thesauruswijzigingen.................................................................................................9
4 NIEUWE VELDEN ................................................................................................................................... 11
4.1 VELDEN OP GEMEENSCHAPPELIJK NIVEAU.............................................................................................. 11
4.2 VELDEN OP LOKAAL NIVEAU .................................................................................................................. 12
4.3 VELDEN VAN HET ONDERZOEKSBLOK..................................................................................................... 14
5 RELATIE TUSSEN BESTAANDE EN NIEUWE VELDEN...................................................................... 17
6 BENODIGDE URL'S................................................................................................................................18
7 MATCHEN VAN PERSOONSNAMEN .................................................................................................... 19
I APPENDIX: METIS EXPORT FORMAT ................................................................................................. 21
II APPENDIX: PICA EXPORT FORMAT.................................................................................................... 23
II.I XSD................................................................................................................................................... 23
II.II XML DOCUMENT ................................................................................................................................. 24
III APPENDIX: THESAURUS TEMPLATES............................................................................................ 26
TEMPLATE ÉÉN NAAM GEVONDEN OF GEKOZEN UIT NAMENOVERZICHT......................................... 27
IV APPENDIX: KWALITEITSEISEN ........................................................................................................ 28
IV.I GEGEVENS.......................................................................................................................................... 28
IV.II PROCEDURES.................................................................................................................................. 28
IV.III DOCUMENTATIE ............................................................................................................................... 30
IV.IV SYSTEEMEISEN................................................................................................................................30
V APPENDIX: SAMENVOEGEN EN SPLITSEN VAN THESAURUSRECORDS...................................... 31
Referenties
- Hans Schoonbrood - Tabellen - kolommen Metis voor DAI
- DAI PID - P1.1
- Format voor Persoonsnamen Thesaurus: OCLC PICA: dn010-persoonsnamenthesaurus-persoonsnamenthesaurus
| Anchor | ||||
|---|---|---|---|---|
|
Inleiding
DAI is de afkorting van Digital Author Identification. De term is afkomstig uit het DARE project Orion waarin
een plan was uitgewerkt om aan onderzoekers die verbonden zijn aan Nederlandse onderzoeksinstellingen
een uniek nummer toe te kennen, een 'digital author identification'. In de database van GGC/NCC (ook
bekend als 'de Pica database) wordt sinds lang een thesaurus onderhouden van persoonsnamen en
personen. In deze thesaurus wordt voor een persoon een record aangemaakt, waarin voorkeursvorm,
volledige naam en voorkomende naamsvarianten worden opgenomen. Aan zo'n record wordt een uniek
nummer toegekend dat ppn (pica productienummer) genoemd wordt. Bibliotheken voegen namen van
auteurs aan de thesaurus toe, wanneer er werken in de collectie worden opgenomen. Het is dan ook
aannemelijk dat onderzoekers die publicaties op hun naam hebben staan, al in de thesaurus zijn opgenomen
en daardoor in feite al een DAI hebben.
...
Het voorliggende document bevat een beschrijving van de werkprocessen bij het gebruik van de thesaurus
ten behoeve van onderzoeksdatabanken en de specificatie van nieuwe velden en subvelden in het format
van de persoonsnamenthesaurus die nodig zijn voor het vastleggen van onderzoekgegevens. De
beschreven velden zijn afgestemd op de structuur en gebruik van de Metis onderzoeksdatabank van de
Rijksuniversiteit Groningen. De gegevens worden vastgesteld in het kader van het DAI project en hebben tot
doel normstellend te zijn voor alle onderzoeksdatabanken van de Nederlandse universiteiten.
| Anchor | ||||
|---|---|---|---|---|
|
Procesbeschrijving
In het pilot project zullen de persoonsgegevens afkomstig uit de Metis databank van de RU Groningen
worden toegevoegd aan de persoonsnamenthesaurus. Na een initiële vulling dient een verwerkingsproces te
worden ingericht dat wijzigingen die in Metis worden aangebracht automatisch in de thesaurus verwerkt.
Tevens wordt een proces ingericht dat wijzigingen die in de thesaurus worden aangebracht kan exporteren
naar een Metis bestand.
| Anchor | ||||
|---|---|---|---|---|
|
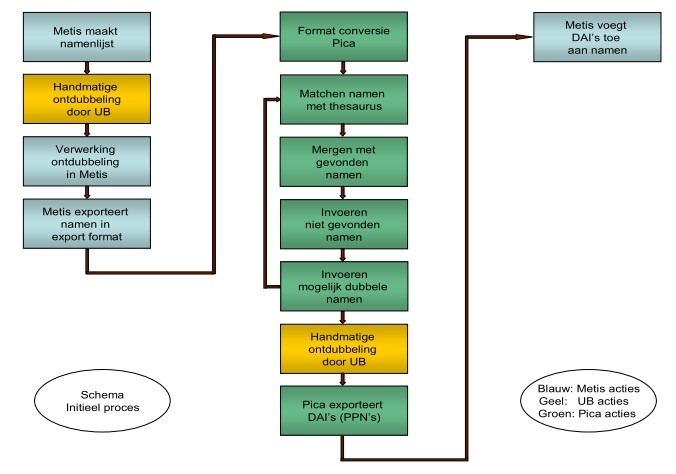
3.1 Initiële vulling
De initiële vulling van de persoonsnamenthesaurus met Metis gegevens zal als volgt plaats vinden:
...
Nadat de Metis gegevens in de thesaurus zijn verwerkt, wordt door Pica een lijst geproduceerd van alle
namen waaraan onderzoeksgegevens zijn toegevoegd. De lijst zal voor elke naam alle naams- en onder-
zoeksgegevens bevatten in een XML structuur. Op basis van deze lijst kunnen de PPN's (Pica productie-
nummers) als DAI's aan de gegevens in de Metis databank worden toegevoegd. Desgewenst kan deze lijst
twee keer worden gemaakt: de eerste keer voor alle namen die gevonden of ingevoerd zijn, de tweede keer
van de namen die door deskundigen van de UB zijn ontdubbeld. Als een Metis databank de aldaar
opgeslagen naamsgegevens wil verrijken met de naamsgegevens uit de thesaurus kan hiervoor dezelfde lijst
gebruikt worden. Zie ook Export van thesauruswijzigingen en Appendix 2.
| Anchor | ||||
|---|---|---|---|---|
|
3.2 Dagelijks gebruik
Na de initiële vulling zullen de Metis gegevens primair in de Metis databank worden onderhouden: als een
onderzoeker al een DAI heeft, zullen wijzigingen in de Metis databank worden aangebracht en zal via een
periodieke batch upload de relevante gegevens aan de betreffende thesaurusrecords worden toegevoegd.
Alleen voor nieuwe onderzoekers zal eerst in de thesaurus gezocht worden, om een DAI op te halen.
| Anchor | ||||
|---|---|---|---|---|
|
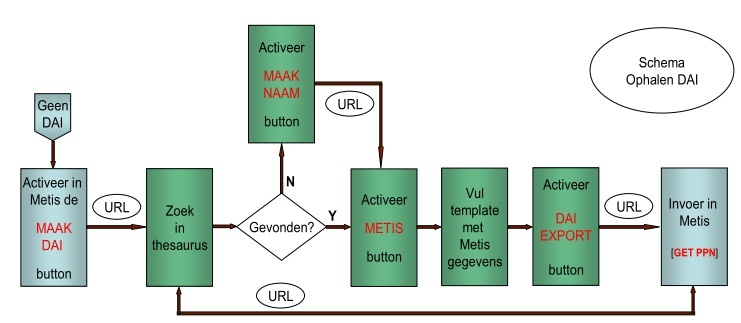
3.2.1 Ophalen DAI
Voor onderzoekers zonder DAI geldt het onderstaande procesverloop:
...
Nadat de door het systeem ingevulde velden door de gebruiker zijn gecontroleerd en zonodig verbeterd en door het systeem zijn geaccepteerd (Merk op dat het invul-template geen velden bevat voor mogelijke naamsvarianten; er wordt vanuit gegaan dat deze bij (nieuwe) onderzoekers die nog geen DAI hebben, nog niet voorkomen. Mogelijke naamsvarianten kunnen in later stadium met behulp van het proces Ophalen van Metis wijzigingen worden toegevoegd. Op de templates is de term DAI vervangen door NTA (Neder-landse Thesaurus voor Auterursnamen)), worden alle gegevens nogmaals getoond met een 'DAI EXPORT"button die een URL activeert om het ppn naar Metis te transporteren. Metis kan het DAI-nummer toevoegenaan de reeds aanwezige naamsgegevens of, indien nodig de zojuist ingevoerde gegevens uit de thesaurus opgehalen door een 'GET PPN' URL te sturen. Afhankelijk van de URL-definitie worden de gegevens in een gelabelde of in een XML presentatie getoond. Onderstaande voorbeeld toont een gelabelde presentatie. 
Gelabelde presentatie met onderzoeksgegevens
| Anchor | ||||
|---|---|---|---|---|
|
3.2.2 Ophalen van Metis wijzigingen
...
| Wiki Markup |
|---|
Bij het verwerken van de updates worden bij elk gevonden thesaurusrecords per universiteit alle aanwezige Metisnamen vervangen door de nieuwe namen en worden alle aanwezige onderzoeksblokken vervangen door de nieuwe. Daarbij blijven de reeds toegekende onderzoeksblok productienummers (epn's) zoveel mogelijk gehandhaafd. \[Bijv.: aan een thesaurusrecord waren drie onderzoeksblokken toegevoegd; er wordt nu een update aangeboden met twee onderzoeksblokken: de eerste twee blokken worden gemuteerd, het derde wordt verwijderd.\] Overwogen kan worden om, bij voorkeur in tweede instantie, na een succesvol verlopen pilot, het FTP proces te vervangen door een web service die het mogelijk maakt om een mutatie in Metis direct naar de thesaurus te sturen. |
| Anchor | ||||
|---|---|---|---|---|
|
3.2.3 Export van thesauruswijzigingen
...
Een speciale vorm van wijzigingen hebben te maken met opschoonacties die het gevolg kunnen zijn van de
initiële vulling maar die ook daarna kunnen voorkomen, wanneer ontdekt wordt dat twee thesaurusrecords
moeten worden samengevoegd of wanneer één thesaurusrecord moet worden gesplitst. Dit kan leiden tot
het overhevelen van de aangehechte onderzoeksblokken naar een ander thesaurusrecord. In die gevallen
krijgt een onderzoeker dus een nieuwe DAI. Samenvoegen en splitsen van naamsrecords is een actie die
alleen door bibliothecarissen mag worden uitgevoerd met de catalogiseer-client WinIBW. Voor consistentie
van de Metis bestanden is het noodzakelijk dat als een onderzoeksblok wordt overgeheveld van het ene
naamsrecord naar het andere en een onderzoeker daardoor een nieuwe DAI krijgt, het oude DAI in het
record van de nieuwe DAI wordt opgenomen. Het betreffende veld is beschreven in hoofdstuk 4.2.
Appendix 4 geeft een procedurebeschrijving voor het splitsen en samenvoegen van namen in de persoons-
namenthesaurus. De daarin genoemde WinIBW scripts zullen ter beschikking worden gesteld door Pica.
| Anchor | ||||
|---|---|---|---|---|
|
4 Nieuwe velden
Omdat onderzoekers verbonden kunnen zijn aan meerdere vakgroepen, faculteiten en universiteiten wordt
bij het vaststellen van de structuur gebruik gemaakt van een technische mogelijkheid die tot nu toe uit-
sluitend voor metadata wordt gebruikt: de mogelijkheid om gegevens op 'exemplaarniveau' vast te leggen.
Bij metadata, zoals de titelgegevens van boeken, wordt het exemplaarniveau gebruikt om een signatuur en
uitleencode of, bij tijdschriften, de aanwezige jaargangen vast te leggen; bij persoonsnamen kan het worden
gebruikt als een 'onderzoeksblok' dat herhaald wordt voor elk werkverband van een onderzoeker. Strekken
de werkverbanden zich uit over meerdere universiteiten dan worden de werkverbanden per universiteit
vastgelegd, waarbij altijd een koppeling wordt gemaakt naar dezelfde persoonsnaam.
Omdat de Metis gegevens primair in de Metis databanken zullen worden onderhouden, worden de uit Metis
afkomstige naamsgegevens apart gehouden van de huidige velden van de persoonsnamenthesaurus. Ook
hiervoor wordt gebruikt gemaakt van een aan titelbeschrijvingen ontleende veldstructuur: de Metis naamge-
gevens zullen worden vastgelegd in 'lokale' velden. Wanneer een onderzoeker aan meerdere universiteiten
verbonden is en dus in meerdere Metis bestanden voorkomt en dus in meerdere Metis bestanden gewijzigd
kan worden, zal voor elke universiteit een apart lokaal blok beschikbaar zijn. Eén en ander leidt tot de
onderstaande recordstructuur:

{anchor:Velden op gemeenschappelijk niveau]
4.1 Velden op gemeenschappelijk niveau
...
+Toelichting:+Dit veld wordt aan en nieuwe naam toegevoegd bij batch invoer, wanneer bij het matchen een naam
gevonden wordt met een gelijkheidswaarde die ligt tussen de waarden die gedefinieerd zijn voor samen-
voegen en voor nieuwe invoer; de ingevoerde naam is dus mogelijk dubbel en veld 038L bevat naast enige
administratieve informatie het PPN van de gevonden naam. Zie ook Matchen van persoonsnamen.
| Anchor | ||||
|---|---|---|---|---|
|
4.2 Velden op lokaal niveau
...
+Toelichting:+1. Dit veld is optioneel; indien aanwezig is minimaal één subveld verplicht; in het thesaurus format begint
dit veld dus met een '=' als alleen de geslachtsaanduiding aanwezig is.
2. Het geboortejaar wordt bij offline matchen gebruikt om te bepalen of dezelfde naamsvormen verschillend
zijn.
| Anchor | ||||
|---|---|---|---|---|
|
4.3 Velden van het onderzoeksblok
...
+Toelichting:+1. Dit veld wordt niet geïndexeerd
| Anchor | ||||
|---|---|---|---|---|
|
5 Relatie tussen bestaande en nieuwe velden
...
Nadat op deze wijze een naam aan de thesaurus is toegevoegd, kan de gebruiker doorgaan met het online
verwerken van de Metis gegevens.
verwerken van de Metis gegevens.
| Anchor | ||||
|---|---|---|---|---|
|
6 Benodigde URL's
In het dagelijkse gebruik van de persoonsnamenthesaurus in relatie met Metis zijn vier URL's en een java
script voorzien om de procesgang te vereenvoudigen:
...
Desgewenst kunnen bovenstaande URL's als Open-URL's of als 'free-format' URL's worden geadministreerd
en onderhouden in de Admin module bij Pica. In het kader van het pilot project zal Pica de benodigde URL's
vastleggen en indien nodig aanpassen. Het java script achter de DAI export button wordt direct aan de
betreffende button gekoppeld en is dus niet via een Admin module te wijzigen.
| Anchor | ||||
|---|---|---|---|---|
|
7 Matchen van persoonsnamen
...
In de voorbereidingsfase zullen de namen die meerdere treffers opleveren niet direct als record met een B-
status worden ingevoerd, maar zullen eerst lijsten worden gemaakt waarmee onderzocht worden of het
matchen nog verder aangescherpt kan worden door, bijvoorbeeld, de index definitie aan een specifieke
situatie aan te passen. De stapsgewijze aanpak is er op gericht om de onder- en bovengrenzen van de
gelijkheidswaarde zo dicht mogelijk bij elkaar te brengen, zodat het aantal namen met een B-status zo klein
mogelijk gehouden kan worden.
| Anchor | ||||
|---|---|---|---|---|
|
I Appendix: Metis export format
...
Opmerkingen:
- Alle gegevens na de REDIRECT dienen gecodeerd (encoded) te worden.
- In een productie omgeving zal het adres van de Pica webpagina, het usernummer en het wachtwoord
gewijzigd worden; usernummer en wachtwoord zullen per onderzoeksinstelling verschillend zijn.
- Mogelijk gebruik van volledige voornamen naast of in plaats van initialen moet na oplevering van een
nieuwe Metis release nog nader worden uitgewerkt.
- Als tekenset wordt UTF8 gebruikt.
| Anchor | ||||
|---|---|---|---|---|
|
II Appendix: Pica export format
In het kader van het DAI project wordt een XML definitie opgesteld van het format dat is beschreven in
hoofdstuk 4, uitgebreid met enkele velden afkomstig uit het thesaurusrecord, zoals het PPN (DAI), de
volledige naam en, indien van toepassing het oude PPN - oude DAI.
De XML export van persoonsnamen met daaraan toegevoegde onderzoeksblokken is zowel in online als in
offline omgeving mogelijk. De specificatie van de XML structuur bestaat uit twee delen: het XML-schema
(XSD) en het bijbehorende XML document.
| Anchor | ||||
|---|---|---|---|---|
|
II.I XSD
| Code Block | ||||
|---|---|---|---|---|
| ||||
<?xml version="1.0" encoding="UTF-8"?>
<\!-\-
XML Schema for validating XML descriptions of the DAI export.
Version : 0.4
Creator : Hans Mugge
Date : 03-04-2006
\-->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<\!-\- definition of simple elements -->
<xs:element name="PPN_003at_797" type="xs:string"/>
<xs:element name="EmployeeName_128Adollara_A10" type="xs:string"/>
<xs:element name="Initials_128Adollard_A10" type="xs:string"/>
<xs:element name="Prefix_128Adollarc_A10" type="xs:string"/>
<xs:element name="Titles_128Adollare_A10" type="xs:string"/>
<xs:element name="PreferredName_128A_A10" type="xs:string"/>
<xs:element name="ResearchNumber_103M_A01" type="xs:string"/>
<xs:element name="DateOfBirth_132Adollara_A30" type="xs:string"/>
<xs:element name="Sex_132Adollarb_A30" type="xs:string"/>
<xs:element name="tPersonalia_028A" type="xs:string"/>
<xs:element name="tNameVariant_028at" type="xs:string"/>
<xs:element name="FunctionName_232Bdollarb_B21" type="xs:string"/>
<xs:element name="FunctionCode_232Bdollara_B21" type="xs:string"/>
<xs:element name="OrganisationName_229Adollara_B10" type="xs:string"/>
<xs:element name="OrganisationCode_229AdollarB_B10" type="xs:string"/>
<xs:element name="StartDate_232Adollara_B20" type="xs:string"/>
<xs:element name="EndDate_232Adollarb_B20" type="xs:string"/>
<xs:element name="daiurl" type="inhoud"/>
<\!-\- definition of complex elements -->
<xs:complexType name="inhoud">
<xs:sequence>
<xs:element name="PersonalData">
<xs:complexType>
<xs:sequence>
<xs:element ref="PPN_003at_797"/>
<xs:element name="Name">
<xs:complexType>
<xs:sequence>
<xs:element ref="EmployeeName_128Adollara_A10"/>
<xs:element ref="Initials_128Adollard_A10"/>
<xs:element ref="Prefix_128Adollarc_A10" minOccurs="0"/>
<xs:element ref="Titles_128Adollare_A10" minOccurs="0"/>
<xs:element ref="PreferredName_128A_A10" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element ref="ResearchNumber_103M_A01"/>
<xs:element ref="DateOfBirth_132Adollara_A30" minOccurs="0"/>
<xs:element ref="Sex_132Adollarb_A30" minOccurs="0"/>
<xs:element name="ThesaurusData">
<xs:complexType>
<xs:sequence>
<xs:element ref="tPersonalia_028A" minOccurs="0"/>
<xs:element ref="tNameVariant_028at" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="FunctionalData">
<xs:complexType>
<xs:sequence>
<xs:element name="Function">
<xs:complexType>
<xs:sequence>
<xs:element ref="FunctionName_232Bdollarb_B21" minOccurs="0" maxOccurs="unbounded"/>
<xs:element ref="FunctionCode_232Bdollara_B21" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="Organisation">
<xs:complexType>
<xs:sequence>
<xs:element ref="OrganisationName_229Adollara_B10" minOccurs="0" maxOccurs="unbounded"/>
<xs:element ref="OrganisationCode_229AdollarB_B10" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="Appointment">
<xs:complexType>
<xs:sequence>
<xs:element ref="StartDate_232Adollara_B20" minOccurs="0" maxOccurs="unbounded"/>
<xs:element ref="EndDate_232Adollarb_B20" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:schema>
|
| Anchor | ||||
|---|---|---|---|---|
|
II.II XML document
| Code Block | ||||
|---|---|---|---|---|
| ||||
<?xml version="1.0" encoding="utf-8" ?>
<catalog banner="NTA">
<record>
<seqnr>1</seqnr>
<sortkey>067745560 </sortkey>
<main>067575560</main>
<PersonalData>
<PPN_003at_797>067745560</PPN_003at_797>
<PPN_103Z_A99>044596941<PPN_103Z_A99>
<Name>
<EmployeeName_128Adollara_A10>Schijndel</EmployeeName_128Adollara_A10>
<Initials_128Adollard_A10>K.J.</Initials_128Adollard_A10>
<Prefix_128Adollarc_A10>van</Prefix_128Adollarc_A10>
<Titles_128Adollare_A10>Prof.Dr.</Titles_128Adollare_A10>
<PreferredName_128A_A10>J.</PreferredName_128A_A10>
</Name>
<ResearchNumber_103M_A01>06817</ResearchNumber_103M_A01>
<DateOfBirth_132Adollara_A30>15-11-1955</DateOfBirth_132Adollara_A30>
<Sex_132Adollarb_A30>M</Sex_132Adollarb_A30>
<ThesaurusData>
<tPersonalia_028A>Karel Jan van Schijndel, 15-11-1955; professor</tPersonalia_028A>
<tNameVariant_028at>Carel Jan van Schijndel</tNameVariant_028at>
</ThesaurusData>
</PersonalData>
<FunctionalData>
<Function>
<FunctionName_232Bdollarb_B21>Universitair hoofddocent</FunctionName_232Bdollarb_B21>
<FunctionCode_232Bdollara_B21>20</FunctionCode_232Bdollara_B21>
</Function>
<Organisation>
<OrganisationName_229Adollara_B10>Huisartsgeneeskunde-vakgroep</OrganisationName_229Adollara_B10>
<OrganisationCode_229Adollarb_B10>22000200</OrganisationCode_229Adollarb_B10>
</Organisation>
<Appointment>
<StartDate_232Adollara_B20>01-10-1991</StartDate_232Adollara_B20>
<EndDate_232Adollarb_B20>01-10-2001</EndDate_232Adollarb_B20>
</Appointment>
<Function>
<FunctionName_232Bdollarb_B21>Onderzoeker</FunctionName_232Bdollarb_B21>
<FunctionCode_232Bdollara_B21>27</FunctionCode_232Bdollara_B21>
</Function>
<Organisation>
<OrganisationName_229Adollara_B10>Oogheelkunde</OrganisationName_229Adollara_B10>
<OrganisationCode_229Adollarb_B10>22700900</OrganisationCode_229Adollarb_B10>
</Organisation>
<Appointment>
<StartDate_232Adollara_B20>01-10-2001</StartDate_232Adollara_B20>
</Appointment>
</FunctionalData>
</record>
</catalog>
|
| Anchor | ||||
|---|---|---|---|---|
|
III Appendix: Thesaurus templates
Deze Appendix bevat voorbeelden van drie templates die getoond worden bij het zoeken in de Neder-
landse Thesaurus voor Auteursnamen. Het template dat gebruikt worden voor het invoeren van Metis
gegevens in the thesaurus en het template dat getoond wordt nadat de in te voeren gegevens zijn
geaccepteerd, staan in Ophalen DAI. 
Template Geen naam gevonden 
Template meerdere namen gevonden 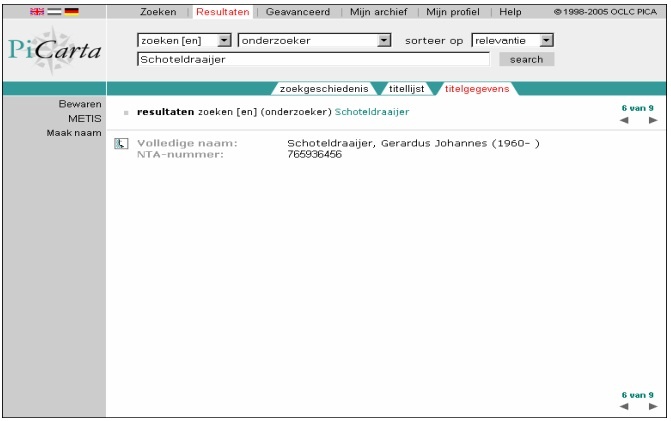
Template één naam gevonden of gekozen uit namenoverzicht
| Anchor | ||||
|---|---|---|---|---|
|
IV Appendix: Kwaliteitseisen
Het DAI project is een pilot project dat bij welslagen als voorbeeld zal dienen voor gelijksoortige projecten
bij de overige Nederlandse onderzoeksinstellingen. Daarom is het van belang om de kwaliteitseisen vast te
stellen waaraan de gegevens, de procedures en de documentatie dienen te voldoen, zodat vervolg-
projecten optimaal gebruik kunnen maken van de resultaten van het pilot project.
| Anchor | ||||
|---|---|---|---|---|
|
IV.I Gegevens
De geformuleerde eisen hebben betrekking op de gegevens die worden aangeleverd vanuit de onderzoeks-
bestanden; de kwaliteit van de gegevens in de persoonsnamenthesaurus wordt geaccepteerd zoals deze
is. Voor de initiële vulling en voor de batch verwerking van in onderzoeksbestanden aangebrachte
wijzigingen gelden de volgende kwaliteitseisen:
...
- DAI (PPN) is een verplicht veld; namen zonder DAI worden in de dagelijkse batch verwerking niet behandeld.
- Namen zonder Voorkeursindicatie worden als naamsvariant toegevoegd; indien al één of meer naamsvarianten in het lokale blok aanwezig zijn, worden identieke naamsvarianten ontdubbeld.
| Anchor | ||||
|---|---|---|---|---|
|
IV.II Procedures
De geformuleerde eisen hebben betrekking op alle procedures die in het pilot DAI project en in vervolg-
projecten voor zullen komen.
...
- De gegevens die in Metis gewijzigd worden dienen dagelijks automatisch verzameld, geconverteerd en op een voor Pica toegankelijke FTP site geplaatst te worden; per onderzoeker worden alle gegevens (alle naamsvarianten en alle onderzoeksgegevens aangeboden.
- De te verwerken gegevens worden geïdentificeerd met de bijbehorende DAI; gegevens zonder DAI worden niet verwerkt
- Een geautomatiseerd proces bij Pica controleert dagelijks de daartoe bestemde FTP sites, converteert de gevonden gegevens naar het thesaurus format en verwerkt de gegevens:
- Namen zonder DAI worden opgeslagen in een error log
- Bij namen met een DAI worden in de thesaurus voor de betreffende bibliotheek / universiteit alle lokale (Metis namen) en exemplaarvelden (onderzoeksgegevens) in de thesaurus vervangen door de nieuwe velden, met voorzover mogelijk, handhaving van de reeds toegekende productienummers (epn's).
| Anchor | ||||
|---|---|---|---|---|
|
IV.III Documentatie
De kwaliteitseisen voor documentatie hebben betrekking op gebruikersdocumentatie, de beschrijving van
de te volgen procedures en de beschrijvingen van de toegepaste datastructuren.
...
- Documentatie van Metis datastructuren en het thesaurus format is in het Nederlands
- Documentatie van het thesaurus format is een onderdeel van de algemene thesaurus documentatie en toegankelijk via de OCLC Pica website
| Anchor | ||||
|---|---|---|---|---|
|
IV.IV Systeemeisen
De volgende kwaliteitseisen worden aan de technische infrastructuur gesteld:
...
- Voor web interface: UTF8
- Voor WInIBW: Intermarc (WinIBW 2.x) of UTF8 (WinIBW 3.x)
| Anchor | ||||
|---|---|---|---|---|
|
V Appendix: Samenvoegen en splitsen van thesaurusrecords
...