...
KE is a co-operative effort between JISC, SURF, DEFF and DFG. International interoperability guidelines for the comparable exchange of usage data is one of these co-operative efforts.
| Warning |
|---|
This wiki has seen a lot of discussion lately with inline comments. For guidelines of how to place such comments, please read the ?guidelines for comments. -- Max Kemman, 26-05-2010 |
| Section | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Date | version | Author | Description | |
|---|---|---|---|---|
2010-03-25 | 0.1 | Peter Verhaar | First draft, based on technical specifications from the OA-Statistics project (written by Daniel Metje and Hans-Werner Hilse), the NEEO project (witten by Benoit Pauwels) and the SURE project (written by Peter Verhaar and Lucas van Schaik) |
|
2010-04-13 | 0.2 | Maurice Vanderfeesten | Added the sections based on the Knowledge Exchange meeting in Berlin. And filled in some additional information to these sections. |
|
2010-04-24 | 0.9 | Peter Verhaar | Revised version, in which comments made by Benoit Pauwels, Hans-Werner Hilse, Thobias Schäfer, Daniel Metje and Paul Needham have been incorporated. |
|
2010-05-18 | 0.9.5 | Peter Verhaar | DRAFT version 1.0 ; comments and layout improvements made by Jochen Schirrwagen, Max Kemman, Peter Verhaar and Maurice Vanderfeesten |
|
Abstract
Guidelines for the exchange of usage statistics from a repository to a central server using OAI-PMH and OpenURL Context Objects.
2010-05-26 | 1.0 | Peter Verhaar | Definitive version 1.0.; Comments made during the phone conference which took place on 25-05-2010 and which was attended by Thobias Schäfer, Hans-Werber Hilse, Jochen Schirrwagen, Marek Imialek, Paul Needham, Peter Verhaar, Maurice Vanderfeesten, Natalia Manola and Lefteris |
|
Abstract
Guidelines for the exchange of usage statistics from a repository to a central server using OAI-PMH and OpenURL Context Objects.
| Info |
|---|
This page is maintained by: KE |
| Info |
This page is maintained by: KE Usage Statistics Work Group |
...
Project | Status |
|---|---|
SURF Sure |
|
PIRUS2 |
|
OA-Statistics |
|
NEEO |
|
COUNTER |
|
PLoS |
|
| Anchor | ||||
|---|---|---|---|---|
|
...
Virtually all web servers that provide access to electronic resources record usage events as part of their log files. Such files usually provide detailed information on the documents that have been requested, on the users that have initiated these requests, and on the moments at which these requests took place. One important difficulty is the fact that these log files are usually structured according to a proprietary format. Before usage data from different institutions can be compared in a meaningful and consistent way, the log entries need to be standardised and normalised. Various projects have investigated how such data harmonisation can take place. In the MESUR project, usage data have been standardised by serialising the information from log files into XML files structured according to the OpenURL Context Objects schema (Bollen and Van de Sompel, 2006). This same standard is recommended in the JISC Usage Statistics Final Report. Using this metadata standard, it becomes possible to set up an infrastructure in which usage data are aggregated within a network of distributed repositories. The PIRUS-I project (Publishers and Institutional Repository Usage Statistics), which was funded by JISC, has investigated how such exchange of usage data can take place. An important outcome of this project was a range of scenarios for the "creation, recording and consolidation of individual article usage statistics that will cover the majority of current repository installations" "Developing a global standard to enable the recording, reporting and consolidation of online usage statistics for individual journal articles hosted by institutional repositories, publishers and other entities (Final Report)", p.3. <http://www.jisc.ac.uk/media/documents/programmes/pals3/pirus_finalreport.pdf>.
In Europe, at least three four projects have experimented with these recommendations and have actually implemented an infrastructure for the central accumulation of usage data: The German OA-Statistics <http://www.dini.de/projekte/oa-statistik
- PIRUS is a project which aims to develop COUNTER-compliant usage reports at the individual article level that can be implemented by any entity (publisher, aggregator, IR, etc.,) that hosts online journal articles. The project will enable the usage of research outputs to be recorded, reported and consolidated at a global level in a standard way.
- Te German OA-Statistics <http://www.dini.de/projekte/oa-statistik/> project, which is funded DINI (Deutsche Initiative für Netzwerk Information), has set up an infrastructure in which various certified repositories across Germany can exchange their usage data.
- In the Netherlands, the project Statistics on the Usage of Repositories <http://www.surffoundation.nl/nl/projecten/Pages/SURE.aspx> (SURE) has a very similar objective. The project, which is funded by SURFfoundation, aimed to find a method for the creation of reliable and mutually comparable usage statistics and has implemented a national infrastructure for the accumulation of usage data.
...
- The Network of European Economists Online <http://www.neeoproject.eu/> (NEEO) is an international consortium of 18 universities which maintains a subject repository that provides access to the results of economic research. As part of this project, extensive guidelines have been developed for the creation of usage statistics. NEEO has also developed an aggregator for usage statistics. The central database is exposed via a web service which can provide information on the number of downloads for each publication.
Whereas these three four projects all make use of the OpenURL Context Object standard, some subtle differences have emerged in the way in which this standard is actually used. Nevertheless, it is important to ensure that statistics are produced in exactly the same manner, since, otherwise, it would be impossible to compare metrics produced by different projects. With the support of Knowledge Exchange, a collaborative initiative for leading national science organisations in Europe, an initiative was started to align the technical specifications of these various projects. This document is a first proposal for international guidelines for the accumulation and the exchange of usage data. The proposal is based on a careful comparison of the technical specifications that have been developed by these three projects.
...
This results in the schema for SURE. See figure 2. The context of this document is limited to the usage data, as sent from the institutional repository to the log harvester.
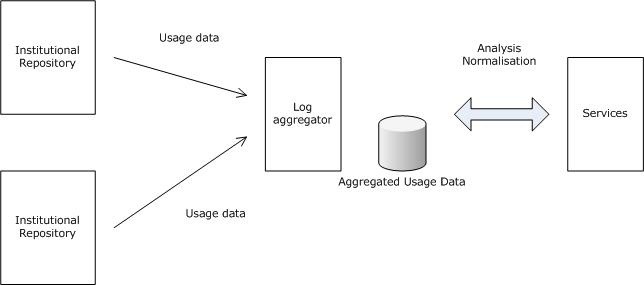

Figure 2.
4. Data format
...
A distinction will be made between the core set and extensions. Data in the core set can be recorded using standard elements or attributes that are defined in the OpenURL Context Object schema. The extensions are created to record aspects of usage events which cannot be captured using the official schema. They have usually been defined in the context of individual projects to meet very specific demands. Nevertheless, some of the extensions may be relevant for other projects as well. They are included here to inform the usage statistics community what additional information could be made available. Naturally, the implementation of all the extension elements are is optional.
| Note |
|---|
There are also other profiles we coud incorporate the best practices from, see http://alcme.oclc.org/openurl/docs/pdf/SanAntonioProfile.pdf |
...
Description | An identification of a specific usage event. |
XPath | ctx:context-object/@identifier |
Usage | Optional |
Format | No requirements are given for the format of the identifier. If this optional identifier is used, it must be (1) opaque and (2) unique for a specific usage event. |
Example | b06c0444f37249a0a8f748d3b823ef2a |
| Note |
|---|
This must be mandatory, at least to identify the repository. This can be done for example to use the repository name as a prefix prior to the opaque identifier. This could be categorised as provenance information. - Jochen |
| Note |
|---|
Usage events are good to use as a control mechanism for the aggregation database to check if duplicate events are harvested. The provenance information of the repository can be found in the <resolver> element, see section 4.1.6. - Peter |
Occurences of child elements in Occurences of child elements in <context-object>
Within a <context-object> element, the following subelements can be used:
Element name | minOccurs | maxOccurs |
Referent | 1 | 1 |
ReferringEntity | 0 | 1 |
Requester | 1 | 1 |
ServiceType | 1 | 1 |
Resolver | 1 | 1 |
Referrer | 0 | 1 |
| Note |
|---|
Just a note: If we make this schema more restrictive, we diverge from the original schema. - Jochen |
| Note |
|---|
This is explained in the beginning of section 4. Dataformat |
4.1.2. <referent>
4.1.2. <referent>
The <referent> element must provide information on the document that is requested. More specifically, it must record the following data elements.
...
Description | A globally unique identification of the resource that is requested must be provided if there is one that is applicable to the document. Identifiers should be independent of the be 'communication protocol'-independent as much as possible. In the case of a request for an object file, the identifier should enable the aggregator to obtain the object's associated metadata file. |
XPath | ctx:context-object/ctx:referent/ctx:identifier |
Usage | Mandatory if applicable |
Format | URI |
Example |
...
Description | The referrer may be categorised on the basis of a limited list of known referrers. All permitted values will be registered in the OpenURL registry. Note | . Concatenating the info:sid namespace with the internet domain name, subdomain name or host name. "Question: When such list exists, must the application check this string with this list? - Maurice |
XPath | ctx:referring-entity/ctx:identifier | |
Usage | Optional | |
Format | A URI that is registered in http://info-uri.info/registry/OAIHandler?verb=GetRecord&metadataPrefix=reg&identifier=info:sid/ | |
Example | info:sid/google |
| Note |
|---|
Peter, the info:sid documentation tells us that this name may refer to an Internet domain name, subdomain name, or host name. The examples at indo-uri.info show
|
info/registry/OAIHandler?verb=GetRecord&metadataPrefix=reg&identifier=info:sid/ | |
Example | info:sid/google |
4.1.4. <requester>
The user who has sent the request for the file is identified in the <requester> element.
...
Description | The user can be identified by providing the IP-address. Including the full IP-address in the description of a usage event is not permitted by international privacy laws. For this reason, the IP-address needs to be obfuscated. The IP-address must be hashed using MD5 encryption. MD5 encryption of IP addresses can easily be hacked. The question if such MD5 encryption secures the privacy sufficiently warrant further research by legal advisors. |
XPath | ctx:context-object/ctx:requester/ctx:identifier |
Usage | Mandatory |
Format | A data-URI, consisting of the prefix "data:,", followed by a 32-digit hexadecimal number. |
Example | data:,c06f0464f37249a0a9f848d4b823ef2a |
...
the privacy sufficiently warrant further research by legal advisors. The IP address of the requester is pseudonymised using encryptions, before it is exchanged and taken outside the web-server to another location. Therefore individual users can be recognised when aggregated from distributed repositories, but cannot be referred back to a 'natural person'. This method may seem consisted with the European Act for Protection of Personal data. The summary can be found here: ? http://europa.eu/legislation_summaries/information_society/l14012_en.htm. Further legal research needs to be done if this method is sufficient to protect the personal data of a 'natural person', in order to operate within the boundaries of the law. |
...
XPath | ctx:context-object/ctx:requester/ctx:identifier |
Usage | Mandatory |
Format | A data-URI, consisting of the prefix "data:,", followed by a 32-digit hexadecimal number. |
Example | data:,c06f0464f37249a0a9f848d4b823ef2a |
<requested/identifier> | C-class Subnet
...