...
It is decided to make a distinction between two 'layers' of robot filtering (see also figure 2):
- Local repositories should make use of a "core" list of robots. It was agreed that a list can probably be created quite easily by combining entries from the lists that are used by COUNTER, AWStats, Universidade do Minho and PLoS. This basic list will filter about 80% of all automated visits.
- Dedicated service providers can carry out some more advanced filtering, on the basis of sophisticated algorithms. The specification of these more advanced heuristics will be a separate research activity. Centralised heuristics should improve confidence in the reliability of the statistics.
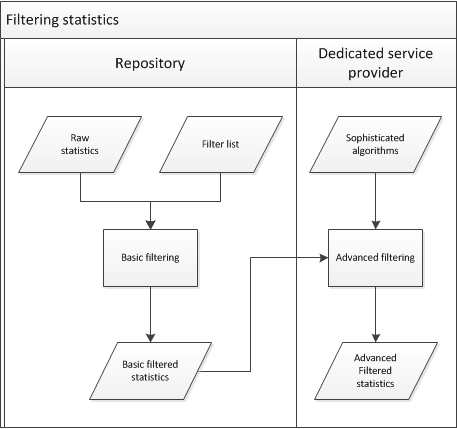 Figure 2
Figure 2
Internet robots will be identified by comparing the value of the User Agent HTTP header to regular expressions which are present in a list of known robots which is managed by a central authority. All entries are expected to conform to the definition of a robot as provided in section 5.2.1. All institutions that send usage data must first check the entry against this list of internet robots. If the robot is in the list, the event should not be sent. It has been decided not to filter robots on their IP-addresses. The reason for this is that IP-addresses change very regularly, and this would make the list very difficult to maintain.
...