...
The institution that is responsible for the repository that contains the requested document is referred to as a usage data provider. Data can be stored locally in a variety of formats, but to allow for a meaningful central collection of data, usage data providers must be able to expose the data in a standardised data format, so that they can be harvested and transferred to a central database. The institution that manages the central database is referred to as the usage data aggregator. The data must be transferred using a well-defined transfer protocol. The data aggregator harvests individual usage data providers minimally on a daily basis, and bears the primary responsibility for synchronising the local and the central data. Ultimately, certain services can be built on the basis of the data that have been accumulated.
The approach that is proposed here coincides largely with scenario B that is described in the final report of PIRUS1 (see figure 1). In this scenario, "the generated OpenURL entries are sent to a server hosted locally at the institution, which then exposes those entries via the OAI-PMH for harvesting by an external third party".
The main advantages of this strategy is that that normalisation does not have to be carried out by individual repositories. Once the data have been received by the log aggregator, the normalisation rules can be applied consistently to all data. Since local repositories only need to make sure that their data can be exposed for harvesting, the implementation should be much easier.
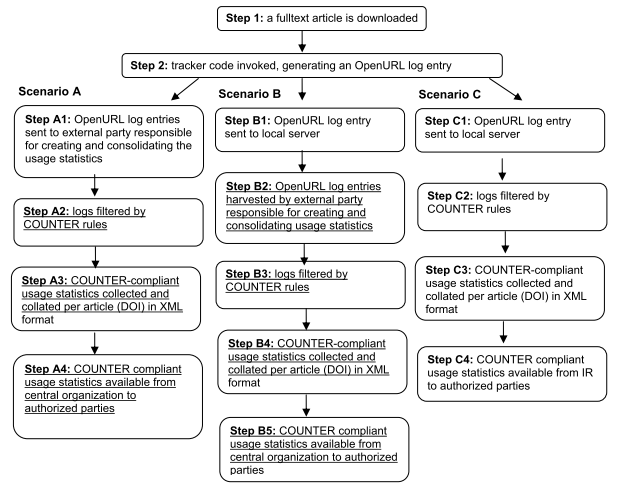
Figure 1. PIRUS1 scenario's (as from the PIRUS final report)
This results in the schema for SURE. See figure 2. The context of this document is limited to the usage data, as sent from the institutional repository to the log harvester.

Figure 2.
| Note |
|---|
please put a reference to the PIRUS1 outcome, and write a little more details about the three scenario's envisioned by PIRUS1 |
...
The data exchange between a data provider and a log aggregator may be based on the widely established OAI Protocol for Metadata Harvesting (OAI-PMH). OAI-PMH was originally designed for the exchange of document metadata. Thus, this standard is mainly adapted in a specific way of handling a certain kind of metadata, as usage data does not meet the general requirements of typical formats used.
In principle, the protocol specifies a data synchronisation mechanism which supports a reliable implementation of one-way data synchronisation. This functionality also fits well for the purpose of usage data transfer.
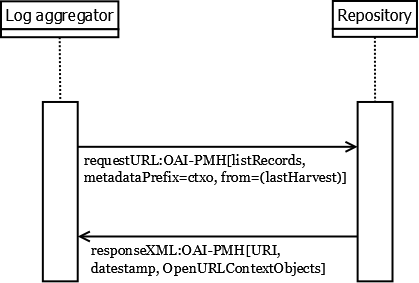
Figure 3.
The document-centric approach of OAI-PMH results in the following central problems when applied to usage data:
...
OAI-PMH is a relatively light-weight protocol which does not allow for a bidirectional traffic. If a more reliable error-handling is required, the Standardised Usage Statistics Harvesting Initiative (SUSHI) must be used. SUSHI http://www.niso.org/schemas/sushi/ was developed by NISO (National Information Standards Organization) in cooperation with COUNTER. This document assumes that the communication between the aggregator and the usage data provider takes place as is explained in figure 14.
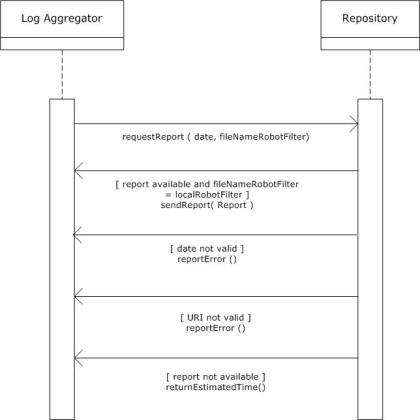
Figure 14.
The interaction commences when the log aggregator sends a request for a report about the daily usage of a certain repository. Two parameters must be sent as part of this request: (1) the date of the report and (2) the file name of the most recent robot filter. The filename that is mentioned in this request will be compared to the local filename. Four possible responses can be returned by the repository.
...
It is decided to make a distinction between two 'layers' of robot filtering (see also figure 25):
- Local repositories should make use of a "core" list of robots. It was agreed that a list can probably be created quite easily by combining entries from the lists that are used by COUNTER, AWStats, Universidade do Minho and PLoS. This basic list will filter about 80% of all automated visits.
- Dedicated service providers can carry out some more advanced filtering, on the basis of sophisticated algorithms. The specification of these more advanced heuristics will be a separate research activity. Centralised heuristics should improve confidence in the reliability of the statistics.
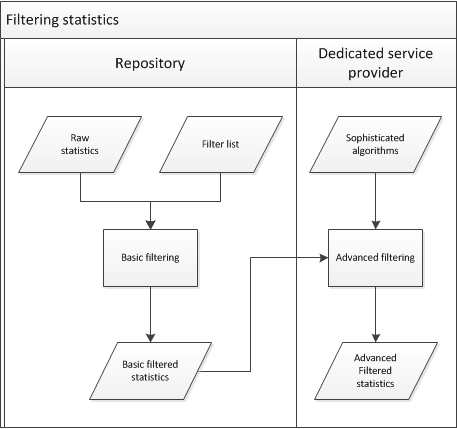
Figure 25.
Internet robots will be identified by comparing the value of the User Agent HTTP header to regular expressions which are present in a list of known robots which is managed by a central authority. All entries are expected to conform to the definition of a robot as provided in section 5.2.1. All institutions that send usage data must first check the entry against this list of internet robots. If the robot is in the list, the event should not be sent. It has been decided not to filter robots on their IP-addresses. The reason for this is that IP-addresses change very regularly, and this would make the list very difficult to maintain.
...