...
Document history
Version | Remarks |
|
|
|
|
July 2006 | First internal version presented to project manangers |
|
1.1 | 2006-08-21: Additional agreements (to metadataprefix naming, datestamp format, set naming, deleted records, resumption token life span, harvest batch size, service window properties, adminEmail for error logging feedback, Prefix & namespace declaration, XML validation, Communication for Repository modification) |
|
1.2 | 2007-03-22: Small changes; | Download PDF |
Remark: The examples used for DIDL; do NOT use them literally! For the precise use of the DIDL document see the current version of the DIDL document specification. That document will overrule all DIDL examples mentioned here.
Acknowledgements This document is largely based on discussions between repository managers and SURF. They have offered their experience and suggestions to create the guidelines as presented in this document.
Source material The guidelines are based on and refer to the Open Archives Initiative Protocol for Metadata Harvesting, Protocol version 2.0. See: http://www.openarchives.org/OAI/openarchivesprotocol.html
The order of presentation of the guidelines is the same as in the protocol text.
When useful, the protocol text is quoted. When the text has been changed, e.g. bold added to highlight some part of the text, this has been indicated between brackets.
...
| Wiki Markup |
|---|
\\ It is important to make a distinction between Item and Record. The protocol text states: "...An item is conceptually a container that stores or dynamically generates metadata about a single resource in *multiple* formats, each of which can be harvested as [<span style="color: #0000ff"><span style="text-decoration: underline; ">records</span></span>|Record] via the OAI-PMH \[...\]A record is metadata expressed in a *single* format. A record is returned in an XML-encoded byte stream in response to an OAI-PMH request for metadata from an item...\[bold added by MF\] \\ Within DARE, the XML-encoded stream is constructed according to the XML-Container specifications. These specifications are given below. \\ The unique identifier identifies an item within a repository. Do not confuse this identifier with the element dc:identifier in Dublin Core. The OAI identifier has a different function: it is used to extract metadata, whereas the DC identifier is used to extract the resource. Schematically: \\ \\ !aoi-pmh-1.JPG!\\ \\ !worddav7194c559f0334a1c27aa6a15f284ac4f.png|height=323,width=500!\\ \\ \\ \\ !aoi-pmh-2.PNG! \\ \\ |
| Anchor | ||||
|---|---|---|---|---|
|
...
The DARE community supports the implementation of the metadataPrefix 'oai_dc' and the the metadataPrefix 'dare_didl'. The schema for the XMLcontainer dare_didl is located at {*}{+} http://www.repository.knaw.nl/web/dare_didl.xsd+*.
The corresponding XML namespace for dare_didl namespace URI currently is http://www.repository.knaw.nl/web/dare_didl.
Every DARE repository must support this 'dare_didl' metadata schema.
The specification of the dare_didl XMLcontainer can be found in the document XMLcontainer1.1.1.pdf. at the location: http://www.darenet.nl/upload.view/DARE_DIDL-XMLcontainter-Specification-v1.1.1.pdf
...
Look at: http://www.openarchives.org/OAI/openarchivesprotocol.html#Set
The OAI-PMH document says the folowing:
Repositories may organize items into sets. Set organization may be flat, i.e. a simple list, or hierarchical.
The DARE agreement is that DARE repositories support at least two type of sets. The 'dare' set and the 'keur' set. Both sets are flat and do not have any hierarchical structure.
The table below shows the highly preferred setName and setSpec that can be used for either set.
| setName | *setSpec* * |
The DARE set | DAREset | dare |
The Keur set | Keurset | keur |
...
- The DAREset contains records that must contain an object that is open accessable for a normal internet user. (What kind of objects/records is left to the local repository.)
- The Keurset contains records, which is a collection of all the published work of the institutions leading scientists. These records do not have to contain any object. When it contains an object it does not have to be open access, but it is highly recommended.
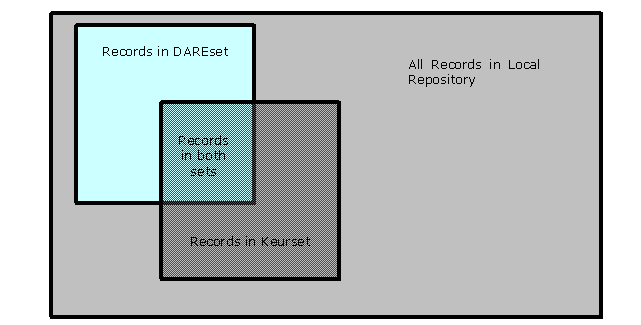 Records in KeursetRecords in DAREsetAll Records in Local RepositoryRecords in both sets
Records in KeursetRecords in DAREsetAll Records in Local RepositoryRecords in both sets
Set Location
The DAREset and the Keurset can each be located at a different location/baseURL.
...
Look at: http://www.openarchives.org/OAI/openarchivesprotocol.html#Idempotency
Repositories that implement resumptionTokens must do so in a manner that allows harvesters to resume a sequence of requests for incomplete lists by re-issuing a list request with the most recent resumptionToken. The purpose of this is to allow harvesters to recover from network or other errors that would otherwise mean that the list request sequence would have to be started again.
The protocol does not mention the life span of a token. A token life span is the time a repository keeps the token stored in memory, along with the resume information. When the life span is to short, the repository does not give the harvester a reasonable time to return to complete the harvest. When this happens the repository does not comply to the protocol, see above: "must do so in a manner that allows harvesters to resume...".
Out of practice: a reasonable time for a token to be kept alive is at least 24 (twenty four) hours.
Along with this life span there is an optimal batch size: see section "Harvest batch size".
...